
robots.txt文件怎么写?最详细的robots.txt写法大全
相信很多学习SEO的朋友都会接触到robots协议文件,对于robots协议文件,很多SEO新手都处于懵逼状态,那么什么是robots协议文件呢?这个文件的格式和写法又是怎样的呢?如何创建robots文件呢?相信一系列的问题一直困扰着大家,今天小编就来给大家分享一下详细的robots.txt写法大全。
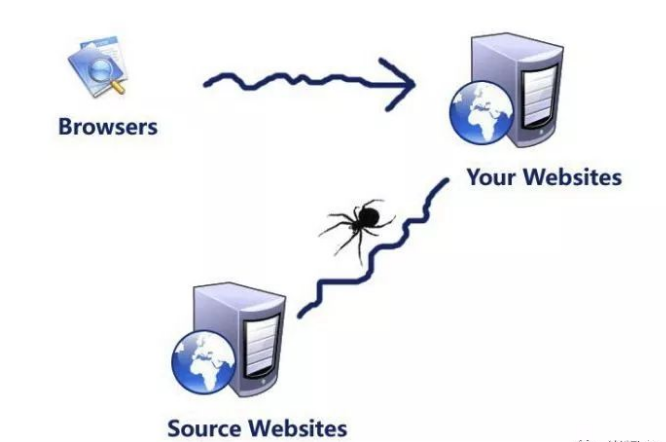
一.什么是robots文件?
robots文件类似与和搜索引擎之间的一个协议,网站能通过该协议文件告诉搜索引擎蜘蛛哪些地方可以抓取,哪些地方不能被索引,站长们通常会把网站不重要的地方禁止搜索引擎抓取,达到一个集权的目的。
二.robots.txt怎么写?
格式例子:
User-agent: *Disallow:
-
User-agent: *:这里的*代表的所有的搜索引擎种类,*是一个通配符,也可以是具体的搜索引擎蜘蛛,如Baiduspider 百度蜘蛛。
2.Allow:是代表允许指令,就算不写指令,搜索引擎也是默认抓取,因此允许指令的作用没其他指令大。
3.Disallow:该指令代表禁止指令,按网站路径或者某一特性进行限制抓取,一般后面会加上禁止访问页面的路径,作用很大。
下面通过写作例子来给大家详细讲解,方便大家理解。
例1.禁止搜索引擎访问网站的所有内容
格式例子:
User-agent: *Disallow: /
其中“/”代表网站的根目录,该意思就是禁止搜索引擎抓取网站根目录下的所有内容。
例2.允许搜索引擎访问网站的所有内容
格式例子:
User-agent: *Allow: /
允许搜索引擎抓取网站所有内容,可以不用写robots文件,或者创建一个空的robots文件,搜索引擎默认抓取。
例3.仅禁止百度蜘蛛(Baiduspider)访问网站
格式例子:
User-agent: BaiduspiderDisallow: /
如果要禁止某一特定的搜索引擎访问网站,就需要在第一排指令填写该搜索引擎蜘蛛名称,而第二排禁止指令进行禁止访问,这个例子主要是限制百度蜘蛛访问网站,而其他搜索引擎则不受限制。
例4.仅允许百度蜘蛛(Baiduspider)访问网站
格式例子:
User-agent: BaiduspiderAllow: /
User-agent: *
Disallow: /
第一段的指令是允许百度蜘蛛访问网站,第二段的指令是禁止所有搜索引擎访问网站,而指令也分优先级,因此要把允许指令写在前面,禁止指令写在后面。
例5.仅允许百度蜘蛛(Baiduspider)和谷歌(Googlebot)访问网站
格式例子:
User-agent: BaiduspiderAllow: /
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
和例4没什么不同,只是多加了一个优先指令而已。
例6.禁止所有搜索引擎蜘蛛(spider)访问指定目录
格式例子:
User-agent: *Disallow: /XXXXXX/
Disallow: /YYYYYY/
这个例子比较特殊,而且涉及的知识点比较多,很多朋友就是没有注意到这些细节,导致一下屏蔽掉了整个网站,这个例子主要屏蔽/XXXXXX/和/YYYYYY/目录,搜索引擎就不会继续访问这两个目录。同时需要注意的是每一个目录都需要一个特殊的指令,必须分开声明,千万不要写成“Disallow: /XXXXXX/ /YYYYYY/”。

例7.允许访问特定目录中的部分目录
格式例子:
User-agent: *Allow: /XXXXXX/YYYY/
Disallow: /XXXXXX/
如果被禁止访问的目录下有着想要搜索引擎抓取的内容,也可以使用允许访问指令,该例子前面允许访问特定的目录,而下面的父级目录被禁止访问的,不过只要优先允许访问特定目录,依然还是能访问的。
例8.使用“*”通配符限制访问特定url
格式例子:
User-agent: *Disallow: /XXXXXX/*.html
如果有很多Url路径需要限制,一个个写禁止指令会花费很长时间,因此可以寻求这些Url路径的共性,然后采用“*”通配符进行限制,例子中的“*”就是代表任意字符都被限制。
例9.使用“$”结束语限制访问特定url
格式例子:
User-agent: *Allow: /*.html$
Disallow: /
前面一排主要是允许搜索引擎访问以html结束的路径页面,“$”代表结束符号,也是非常重要的。
例10.禁止访问网站中所有的动态页面
格式例子:
User-agent: *Disallow: /*?*
一般动态路径都包含"?"符号,因此可以限制带有"?"符号,就等于限制了搜索引擎抓取网站中所有动态路径。
例11.仅禁止百度蜘蛛(Baiduspider)抓取网站上所有的图片
格式例子:
User-agent: BaiduspiderDisallow: /*.jpg$
Disallow: /*.png$
Disallow: /*.jpeg$
Disallow: /*.gif$
Disallow: /*.bmp$
该指令是仅允许抓取网页内容,禁止抓取图片,当然仅限于百度搜索引擎,其他搜索引擎照样能抓取图片。
例12.仅允许百度蜘蛛(Baiduspider)抓取网页内容和jpg格式图片
格式例子:
User-agent: BaiduspiderAllow: /*.jpg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.jpeg$
Disallow: /*.bmp$
该指令是允许百度搜索引擎抓取网页内容和jpg格式的图片,不允许抓取其他格式的图片。
例13.仅禁止百度蜘蛛(Baiduspider)抓取jpg格式图片
格式例子:
User-agent: BaiduspiderDisallow: /*.jpg$
注意:每一个指令的“:”符号后面,都要空一个空白字符,同时每一个指令前面的第一个英文字母都是大写的,后面跟上小写的,这两点是非常重要的,需要大家注意。
三、如何创建robots.txt文件?
1.如果网站根目录下没有robots文件,可以新建一个txt纯文本文件,然后命名为“robots.txt”,然后在该文本中编辑相应指令,通过ftp上传到网站根目录即可。
2.如果网站本身就有robots文件,则可以下载文件进行修改,然后在上传覆盖即可。注意,robots文件一定要放在根目录下。
推荐资讯
- 阿里云ECS建网站(建站)超详细全套完整2023-12-20
- 腾讯云服务器搭建网站2023-12-20
- SEO流程框架(保姆级教程)2023-09-17
- 网站被挂马怎么处理?2023-06-14
- seo和sem的关系2023-06-14
- seo的具体环节有哪些?2023-06-14
- seo的全过程2023-06-14
- SEO运营总结目录;2022-11-25
- 什么是SEO?了解SEO的基础知识!2022-11-25
- 网站搬家迁移2022-08-14
服务推荐





- 全网营销 (网站+公众号+B2B平台+论
- 服务价格:¥16800
- 热度:

- 查看详情

- 热度:

- 查看详情>>

- 热度:
- 查看详情>>

- 热度:
- 查看详情>>

- 热度:
- 查看详情>>

- 热度:
- 查看详情>>

- 热度:
- 查看详情>>

- 热度:
- 查看详情>>

- 热度:
- 查看详情>>

- 热度:
- 查看详情>>

- 热度:
- 查看详情>>
















左道网络为你提供网址搭建、网站优化、竞价托管、自媒体运营、短视频运营、海报设计、小程序搭建综合服务。
Copyright © 1998-2022 云南网络营销网 版权所有 滇ICP备2022006057号
联系电话1:15288288485/联系电话2:16687094569


在线留言(留言后专人第一时间快速对接)
已有 926 名客户选择了我们